6 Mapas
require(tidyverse) # Para manipulación de nuestros datos
require(sf) # Para manipulación de nuestros datos (espaciales)
require(ggplot2)
require(ggthemes) # Sirve para dejar más lindos nuestros gráficos de ggplot
require(RColorBrewer) # Ídem
require(leaflet) # Sirve para hacer mapas intereactivos
require(tmap)6.1 Trabajando con el censo 2010
6.1.1 Datos del censo 2010
Hasta ahora hemos hecho énfasis en el dataset de propiedades de Properati en CABA. Vamos a retomar ese tema un poco más adelante, pero para volver a entrenar las fases anteriores del proceso de data science (importar, transformar y graficar datos) vamos a utilizar los datos del Censo 2010, provistos por http://datar.noip.me/. Debido a que el archivo .rar pesa 400mb - y que varias de las actividades que vamos a hacer probablemente no puedan ejecutarse en todas las computadores del curso, por un tema de memoria RAM - lo que hice fue, al igual que la clase 2, tomar una muestra estratificada del censo de tal manera que puedan recorrer todo el camino.
El archivo con la muestra estratificada pueden descargarlo desde nuestro repositorio. Para replicar la experiencia que tendrían si descargaran los datos del censo desde http://datar.noip.me/, se trata de un .rar cuyo contenido deberían extraer en la carpeta del proyecto (o alguna subcarpeta). Hay ocho archivos .csv, que eventualmente usaremos, y un archivo descripción.txt, donde tenemos la información sobre qué es cada variable y cuales son los valores que pueden tomar. Además, existe una carpeta que se llama “labels”, donde se encuentra la información sobre qué significa cada uno de los valores de las variables para un subconjunto de ellas. De cualquier manera, no lo vamos a usar ya que esa información se encuentra en el archivo .txt.
Pueden acceder al archivo .rar que contiene todos estos archivos desde https://github.com/datalab-UTDT/datasets/raw/master/CNPHyV-2010Sample.rar. Recuerden que deben descargarlo en alguna de las carpetas dentro de sus proyectos.
El censo del 2010 en Argentina distingue entre las siguientes tres entidades principales:
- Viviendas. Según el INDEC, una vivienda es “un espacio donde viven personas”. En realidad, un lugar donde podrían vivir personas, pero al momento del censo pueden estar ocupados o desocupadas.
- Hogares. Un hogar para el INDEC es una persona o grupo de personas que viven 1) bajo el mismo techo y 2) comparten los gastos de alimentación.
- Individuos
Los datos vinculados a cada una de estas unidades están almacenadas en diversos archivos .csv: “VIVIENDA.csv”, “HOGAR.csv” y “PERSONA.csv”. Comencemos primero con las viviendas:
Estén atentos que estamos usando la función read_delim en lugar de read_csv. La principal diferencia es que con read_delim() podemos indicar con el argumento delim el caracter que marca la separación entre datos
## Rows: 52,508
## Columns: 13
## $ VIVIENDA_REF_ID <dbl> 17831, 32505, 99783, 8879, 78302, 12649, 87383, 50584, 4089, 4494, 91055, 58043, 131148, 108284, 23444,...
## $ RADIO_REF_ID <dbl> 61, 88, 236, 45, 181, 51, 204, 121, 27, 29, 214, 133, 329, 259, 72, 221, 66, 264, 121, 117, 285, 122, 3...
## $ TIPVV <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ V01 <dbl> 4, 4, 1, 4, 4, 4, 4, 4, 1, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 1...
## $ V02 <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ V00 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ URP <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ INCALSERV <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3...
## $ INMAT <dbl> 1, 1, 1, 1, 1, 2, 1, 1, 2, 2, 3, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 2, 1, 1, 2, 1, 1, 2...
## $ MUNI <dbl> 20010001, 20010001, 20010001, 20010001, 20010001, 20010001, 20010001, 20010001, 20010001, 20010001, 200...
## $ LOCAL <dbl> 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001010, 2001...
## $ INCALCONS <dbl> 1, 1, 1, 1, 1, 2, 1, 1, 2, 3, 2, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 3, 1, 1, 1, 1, 2, 1, 1, 2, 1, 1, 2...
## $ TOTHOG <dbl> 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...Son 52.508 viviendas, con 13 variables. Varias de ellas nos dan información sobre la ubicación geógrafica. Por ejemplo, RADIO_REF_ID es una variable que vincula a cada vivienda con un determinado radio censal, la unidad geográfica de menor tamaño del censo. La muestra con la que estamos trabajando está estratificada a nivel de departamentos, por lo que pueden existir radios censales para los cuales no exista ninguna información. VIVIENDA_REF_ID identifica de manera única a las viviendas, y será de mucha utilidad más tarde para usar información sobre los hogares y los invididuos.
Con respecto a los datos específicos sobre las viviendas, dos de los más interesantes son INCALSERV, e INCALCONS que nos indican el índice de calidad de conexiones a servicios públicos y el índice de calidad de la construcción de la vivienda, respectivamente. La página Redatam (https://redatam.indec.gob.ar/argbin/RpWebEngine.exe/PortalAction?&MODE=MAIN&BASE=CPV2010B&MAIN=WebServerMain.inl) del Censo 2010 de Argentina nos permite ver cuáles son todas las variables del “cuestionario básico” y las variables que pueden tomar. En este caso, ambas variables pueden tomar los valores 1,2 o 3 (“Satisfactoria”, “Básica” e “Insuficiente”).
Dejemos por un lado las variables referidas a los índices de calidad. Recuerden que estamos trabajando con una muestra estratificada a nivel departamental, por lo que nuestros gráficos tendrán más sentido a esa agregación o mayor (nivel provincial). Lamentablemente, nuestro dataset de viviendas no nos dice a cuál departamento pertenece cada vivienda, pero, como anticipamos anteriormente, sí nos da información sobre su radio censal en RADIO_REF_ID. Los radios censales se agrupan en fracciones censales, que a su vez se asocian a departamentos y estos últimos a las provincias. Como les dije, hoy vamos a leer muchos archivos para prácticar ¡Allá vamos!
radios <- read_delim(file = 'data/CNPHyV-2010Sample/RADIO.csv', delim=";")
fracciones <- read_delim(file = "data/CNPHyV-2010Sample/FRAC.csv", delim=";")
# El parámetro LOCALE nos permite especificar algunas caracteristicas sobre cómo leer los datos, en este caso pedimos que el encoding sea UTF-8. Además, usamos trimws() para sacar alguno de los espacios que tiene la columna NOMDPTO
departamentos <- read_delim(file = "data/CNPHyV-2010Sample/DPTO.csv", delim=";",locale = locale(encoding = "UTF-8")) %>%
mutate(NOMDPTO=trimws(NOMDPTO))Bien, si no tuvieron ningun problemas con los separadores - ni con la dirección del archivo -, ya están en condiciones de observar qué contenido tiene cada uno de nuestros objetos. Veamos:
## Rows: 52,382
## Columns: 3
## $ RADIO_REF_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,...
## $ FRAC_REF_ID <dbl> 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3...
## $ IDRADIO <chr> "01", "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17"...radios es un Data Frame con 3 variables y 52.382 observaciones. Cada una de las observaciones corresponde a un radio único, por lo que en el Censo 2010 los radios censales fueron levemente superior a 52.000. Como vemos, cada radio censal se asocia a una única fracción censal. Veamos ahora nuestro data frame que contiene información sobre las fracciones.
## Rows: 5,428
## Columns: 3
## $ FRAC_REF_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, ...
## $ DPTO_REF_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2,...
## $ IDFRAC <chr> "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17", "18",...Bien, las fracciones censales son 5.428 y cada una de ellas corresponde a un determinado departamento, que podemos a su vez consultar en el data frame homónimo:
## Rows: 527
## Columns: 5
## $ DPTO_REF_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, ...
## $ PROV_REF_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,...
## $ IDDPTO <chr> "001", "002", "003", "004", "005", "006", "007", "008", "009", "010", "011", "012", "013", "014", "015", "0...
## $ DPTO <dbl> 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 6028, 6035, 6091,...
## $ NOMDPTO <chr> "Comuna 01", "Comuna 02", "Comuna 03", "Comuna 04", "Comuna 05", "Comuna 06", "Comuna 07", "Comuna 08", "Co...El data frame departamentos cuenta con más información, ya que también incluye el nombre de los departamentos.
Ya tenemos nuestro camino para unir a las viviendas con sus respectivos departamentos: tenemos que combinar los radios con las fracciones y luego las fracciones con sus departamentos. Por suerte, tidyverse nos brinda una función importante para lograr esto: left_join. Veamos cómo funciona:
## Rows: 52,382
## Columns: 5
## $ RADIO_REF_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,...
## $ FRAC_REF_ID <dbl> 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3...
## $ IDRADIO <chr> "01", "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17"...
## $ DPTO_REF_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ IDFRAC <chr> "01", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02"...Si se fijan bien, el data frame radios ahora tiene 5 variables: las 3 iniciales y dos nuevas: DPTO_REF_ID e IDFRAC. La cantidad de filas es la mismas que antes ¿Qué es lo que hace la función left_join? Para cada observación del primer data frame que le pasamos (radios) incorpora las variables que están en el segundo dataset que le pasamos (fracciones) usando una o más columnas que sirven para unir ambos data frames, en este caso FRAC_REF_ID.
Uno podria pensar que como ahora tenemos el ID del departamento ya podemos unir a las viviendas con los departamentos. Sin embargo, como vamos a ver más adelante los ids de los departamentos en estas tablas no coinciden con los del shapefile disponible en el mismo repositorio. Por esta razón, vamos a tener que trabajar con los códigos de los departamentos. Para esto, debemos hacer un nuevo left_join entre las fracciones censales y el data frame con el listado de departamentos para obtener el código:
radios <- left_join(radios, departamentos %>% select(DPTO_REF_ID, DPTO), by = c("DPTO_REF_ID"))
glimpse(radios)## Rows: 52,382
## Columns: 6
## $ RADIO_REF_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,...
## $ FRAC_REF_ID <dbl> 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3...
## $ IDRADIO <chr> "01", "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17"...
## $ DPTO_REF_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ IDFRAC <chr> "01", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02", "02"...
## $ DPTO <dbl> 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001...Ya podemos vincular las viviendas a los departamentos, ya que nuestro data frame de viviendas tiene una variable que identifica a cada radio, y nuestro data frame que acabamos de crear contiene el mismo ID y lo asigna al departamento correspondiente. Antes de aplicar el left_join, es importante marcar que siempre nos devuelve todas las columnas de ambos dataframes. Esto es ineficiente en muchos casos, por ejemplo a nosotros solo nos interesa agregar la información sobre DPTO (el código del departamento). La forma más fácil de evitar hacer innecesariamente grande nuestro dataset es eliminar las variables antes de hacer el join:
viviendas <- left_join(x = viviendas,
y = radios %>% select(RADIO_REF_ID, DPTO),
by = "RADIO_REF_ID")
str(viviendas) # En la 14va columna tenemos el departamento al que pertenece## tibble [52,508 x 14] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ VIVIENDA_REF_ID: num [1:52508] 17831 32505 99783 8879 78302 ...
## $ RADIO_REF_ID : num [1:52508] 61 88 236 45 181 51 204 121 27 29 ...
## $ TIPVV : num [1:52508] 1 1 1 1 1 1 1 1 1 1 ...
## $ V01 : num [1:52508] 4 4 1 4 4 4 4 4 1 1 ...
## $ V02 : num [1:52508] 1 1 1 1 1 1 1 1 1 1 ...
## $ V00 : num [1:52508] 0 0 0 0 0 0 0 0 0 0 ...
## $ URP : num [1:52508] 1 1 1 1 1 1 1 1 1 1 ...
## $ INCALSERV : num [1:52508] 1 1 1 1 1 1 1 1 1 1 ...
## $ INMAT : num [1:52508] 1 1 1 1 1 2 1 1 2 2 ...
## $ MUNI : num [1:52508] 2e+07 2e+07 2e+07 2e+07 2e+07 ...
## $ LOCAL : num [1:52508] 2e+06 2e+06 2e+06 2e+06 2e+06 ...
## $ INCALCONS : num [1:52508] 1 1 1 1 1 2 1 1 2 3 ...
## $ TOTHOG : num [1:52508] 1 1 1 1 1 2 1 1 1 1 ...
## $ DPTO : num [1:52508] 2001 2001 2001 2001 2001 ...
## - attr(*, "spec")=
## .. cols(
## .. VIVIENDA_REF_ID = col_double(),
## .. RADIO_REF_ID = col_double(),
## .. TIPVV = col_double(),
## .. V01 = col_double(),
## .. V02 = col_double(),
## .. V00 = col_double(),
## .. URP = col_double(),
## .. INCALSERV = col_double(),
## .. INMAT = col_double(),
## .. MUNI = col_double(),
## .. LOCAL = col_double(),
## .. INCALCONS = col_double(),
## .. TOTHOG = col_double()
## .. )6.1.2 Polígonos del Censo 2010
El caso del censo es uno de los más clásicos cuando queremos cruzar datos que pertenecen a una determinada organización territorial pero que no tienen incluido un shapefile o geojson (otra forma de guardar datos espaciales). En ese caso debemos encontrar los polígonos de cada región administrativa (departamentos) y unir los polígonos con los datos (joinearlos), del mismo modo que hicimos anteriormente. Pueden descargar estos datos desde aquí. Ya saben como leer shapefiles a R con read_sf()
## Rows: 527
## Columns: 11
## $ link <chr> "02001", "02002", "02003", "02004", "06091", "74056", "02005", "02006", "06147", "02007", "02008", "02009", ...
## $ codpcia <chr> "02", "02", "02", "02", "06", "74", "02", "02", "06", "02", "02", "02", "06", "02", "06", "06", "02", "02", ...
## $ departamen <chr> "Comuna 1", "Comuna 2", "Comuna 3", "Comuna 4", "Berazategui", "La Capital", "Comuna 5", "Comuna 6", "Carlos...
## $ provincia <chr> "Ciudad Autónoma de Buenos Aires", "Ciudad Autónoma de Buenos Aires", "Ciudad Autónoma de Buenos Aires", "Ci...
## $ mujeres <chr> "107789", "89890", "101936", "115079", "165636", "104417", "98199", "97206", "11381", "118110", "97692", "85...
## $ varones <chr> "98097", "68042", "85601", "103166", "158608", "99602", "80806", "78870", "10856", "102481", "89545", "76207...
## $ personas <chr> "205886", "157932", "187537", "218245", "324244", "204019", "179005", "176076", "22237", "220591", "187237",...
## $ hogares <chr> "84468", "73156", "80489", "76455", "93164", "58559", "76846", "75189", "7775", "81483", "58204", "56495", "...
## $ viv_part <chr> "130771", "107967", "101161", "82926", "96025", "62166", "92750", "93368", "9446", "89520", "55377", "63322"...
## $ viv_part_h <chr> "78360", "70869", "75605", "69680", "86248", "53317", "73226", "72942", "7504", "73034", "48631", "52355", "...
## $ geometry <MULTIPOLYGON [°]> MULTIPOLYGON (((-58.37501 -..., MULTIPOLYGON (((-58.40084 -..., MULTIPOLYGON (((-58.39365 -...,...Para hacer el join precisamos identificar la variable que tiene a los ids de los departamentos. En este caso podemos ver que la variable link (es una variable factor) tiene 527 valores (la misma cantidad de departamentos que tiene Argentina) y toma los mismos valores que nuestra variable en el dataset de viviendas (DPTO). Sin embargo, están en distinto formato: una es una variable numérica, mientras que la otra es una variable factor. Para hacer el join precisamos que ambas variables tengan el mismo formato:
Como no nos importa ninguna de las otras variables con las que viene el objeto sf, con excepción de su geometría (obviamente) y la varible “link” que contiene la información necesaria para hacer el join, vamos a quedarnos solo con ellas. Usemos lo que ya conocemos:
6.1.3 Uniendo los datos con sus polígonos
Una de las opciones que podrían hacer es unir las observaciones de las viviendas a cada uno de los polígonos que pertenece. Sin embargo, esto no es eficiente. Lo mejor es hacer nuestras transformaciones sobre el dataset de viviendas para luego hacer la unión con los polígonos cuando tengamos un dataset con los indicadores por departamento. Las operaciones de join suelen ocupar mucho espacio de memoria (y tiempo), especialmente cuando se trata de muchas filas y columnas. Además, siempre que se pueda es mejor hacer nuestras transformaciones de datos cuando no son objetos Simple Feature.
Vamos a generar un indicador de “mala infraestructura”. En rigor, vamos a medir la proporción de viviendas que presentan un índice de calidad de servicios igual a 3 (insuficiente) o de calidad de construcción de viviendas igual a 3 (insuficiente). Luego, vamos a agrupar el dataset por los departamentos. Por suerte, ya sabemos como hacerlo con tidyverse:
datosCalidad <- viviendas %>%
mutate(indiceCalidad = ifelse(INCALSERV == 3 | INCALCONS == 3, 1, 0)) %>%
group_by(DPTO) %>%
summarise(indiceCalidad = round(sum(indiceCalidad)/n()*100))## `summarise()` ungrouping output (override with `.groups` argument)## tibble [526 x 2] (S3: tbl_df/tbl/data.frame)
## $ DPTO : num [1:526] 2001 2002 2003 2004 2005 ...
## $ indiceCalidad: num [1:526] 9 2 6 7 5 1 4 10 1 1 ...Tenemos el porcentaje de viviendas que tienen alguno de estos dos índices como insuficientes. Para esto usamos la función n(), que es sumamente útil: nos dice la cantidad de casos que existe para cada grupo. Es especialmente interesante cuando queremos calcular proporciones, ya que al ponerlo en el denominador, solo nos queda poner en el numerador la cantidad de casos que cumplen con nuestro criterio (que lo hicimos con la función sum()). Luego multiplicamos por 100, porque así se representan los datos en porcentajes.
Ahora sí, ya podemos hacer la unión con nuestro dataset espacial:
¡Importante! Vean que pudimos asignar a las observaciones a sus polígonos sin necesidad de hacer un join espacial, como hicimos con los inmuebles y los polígonos de CABA en la anterior clase. Esto se puede hacer siempre que haya un ID que nos permita asignarlo. En general, esto no existe y hay que trabajar con los nombres de las entidades (en este caso, los departamentos).
Antes de seguir, vamos a agregar los nombres de los departamentos, que nos será útil para las visuaizaciones:
datosCalidad<- left_join(datosCalidad,
departamentos %>% select(DPTO, NOMDPTO),
by = c("link"="DPTO"))
str(datosCalidad)## tibble [527 x 4] (S3: sf/tbl_df/tbl/data.frame)
## $ geometry :sfc_MULTIPOLYGON of length 527; first list element: List of 1
## ..$ :List of 1
## .. ..$ : num [1:539, 1:2] -58.4 -58.4 -58.4 -58.4 -58.4 ...
## ..- attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"
## $ link : num [1:527] 2001 2002 2003 2004 6091 ...
## $ indiceCalidad: num [1:527] 9 2 6 7 25 21 5 1 30 4 ...
## $ NOMDPTO : chr [1:527] "Comuna 01" "Comuna 02" "Comuna 03" "Comuna 04" ...
## - attr(*, "sf_column")= chr "geometry"
## - attr(*, "agr")= Factor w/ 3 levels "constant","aggregate",..: NA NA NA
## ..- attr(*, "names")= chr [1:3] "link" "indiceCalidad" "NOMDPTO"6.2 Haciendo visualizaciones
Hace unos años uno podría haber dicho que una de las desventajas de R es su falta de realizar visualizaciones de relevancia, ni siquiera hablar de trabajar con visualizaciones interactivas. Ejecuten el siguiente código, tal como hace Lovelace en su libro de Geocomputation, y verán que ya no es el caso:
popup = c("Nuestra clase")
leaflet() %>%
addProviderTiles("NASAGIBS.ViirsEarthAtNight2012") %>%
addMarkers(lng = c(-58.381592),
lat = c(-34.603722),
popup = popup) %>%
setView(lng = -58.381592, lat =-34.603722, zoom = 4)Este mapa interactivo es posible gracias a la implementación de Leaflet para R (deben tener instalado y cargado en la sesión el paquete homónimo para poder correrlo). Hoy en día R nos da la posiblidad de realizar excelentes gráficos y visualizaciones. Vamos a presentar los principales paquetes para hacerlo durante las próximas dos clases, haciendo énfasis en los mapas.
6.2.1 Ggplot2
Hace tiempo que ggplot2 se ha convertido en el paquete de referencia para hacer visualizaciones. En distintas partes de nuestro curso lo he mostrado, en la mayoría de veces sin su aplicación a datos espaciales. En esta clase voy a mostrar que es posible hacer gráficos con ggplot2 y sf, pero más tarde también voy a mostrar que sus funcionalidades ampliamente exceden esta extensión.
Ggplot2 (al igual que tmap y leaflet) organiza su trabajo en capas. En general, primero pasamos los datos y después vamos agregando “mejoras incrementales”. Siempre debemos comenzar con ggplot() y luego indicar qué tipo de gráfico queremos:

Como vemos, los departamentos de la Antártida y las Islas del Atlántico Sur no tienen mucho sentido para nuestras visualizaciones, y además nuestra visualización. Vamos a filtrarlas para lo que resta de la clase:
datosCalidad <- datosCalidad %>%
filter(!NOMDPTO %in% c('Islas del Atlántico sur', "Antártida Argentina"))
ggplot(data = datosCalidad) + geom_sf()
Mucho mejor. Ahora debemos rellenar los polígonos con nuestras variables, en este caso el índicador de deficiencias en la calidad de la construcción o servicios de las viviendas. Esto lo hacemos SIEMPRE dentro de la función aes(), en este caso con fill:
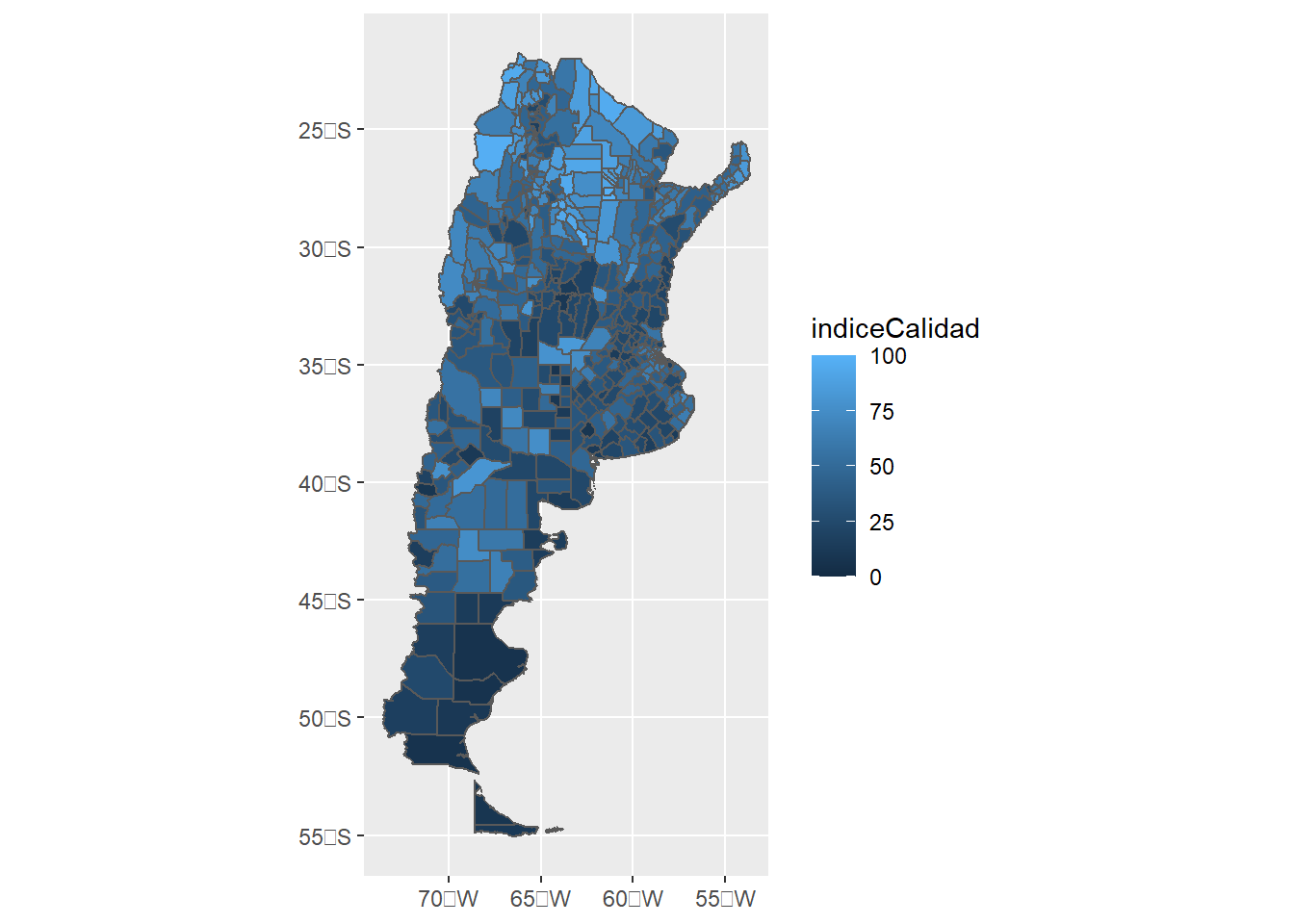
Lo que hace aes() es pasarle a ciertos objetos del gráfico (en este caso, fill) los valores que debe tomar. En español, lo que le decimos es “de ahora en más, rellená todos los polígonos en base a los valores de la variable indiceCalidad”. Luego, le decimos que grafique las geometrias de sf, simplemente pasándole el argumento “geom_sf”. Los colores que tiene por default son bastante malos y no queda muy en claro el valor que le corresponde a cada departamento. Vamos a empezar a hacer uso de algunas mejoras en los gráficos de ggplot2
ggplot(data = datosCalidad, aes(fill = indiceCalidad)) +
geom_sf(colour = "white") +
scale_fill_gradientn(colours = brewer.pal(n = 5, name = "Blues"),
name = "Viviendas de calidad \ninsuficiente (%)")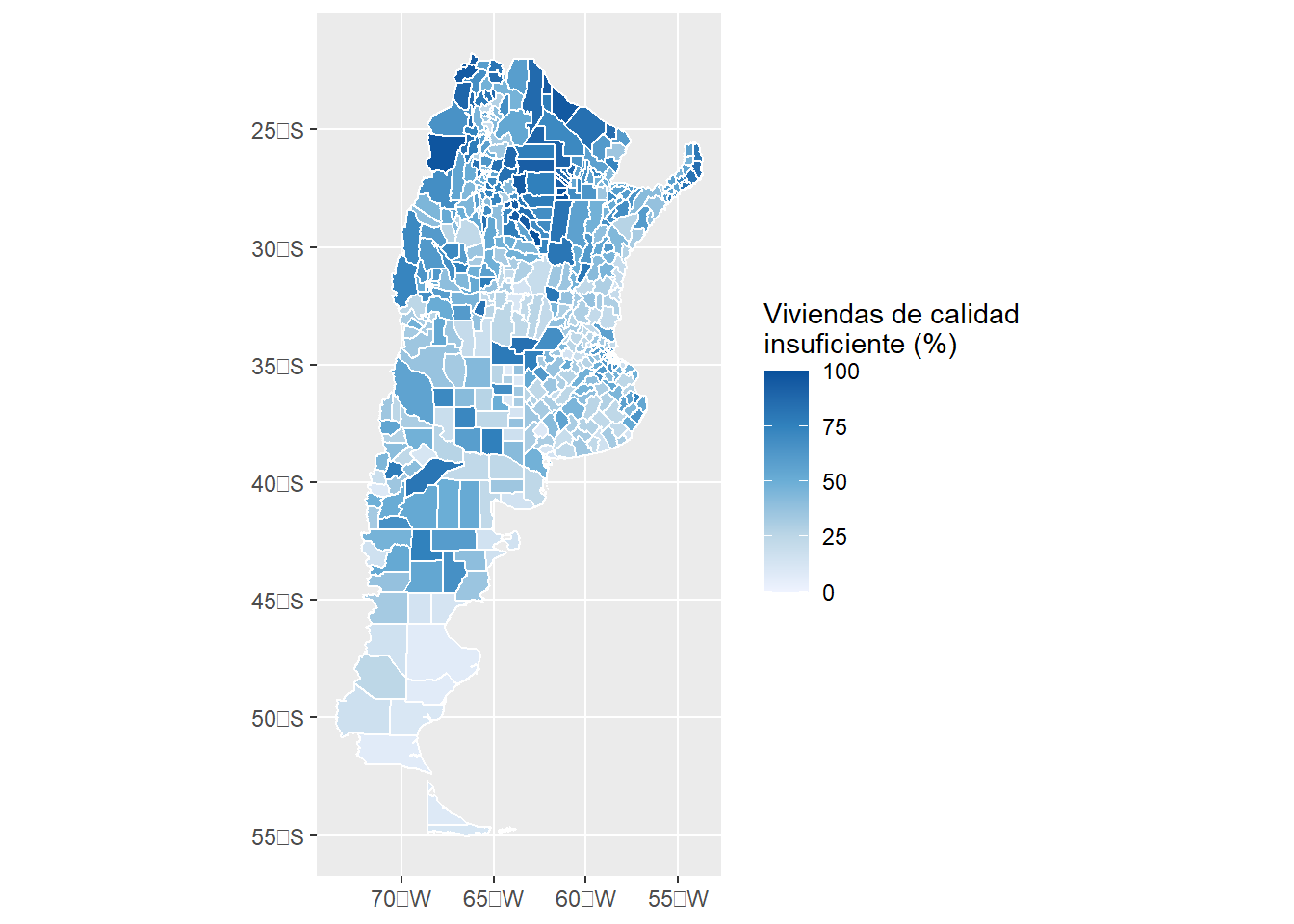
Bastante mejor. Lo que hicimos fue 1) cambiar el color de los límites entre los polígonos (colour = “white”) y también cambiamos los colores correspondientes a cada uno de los valores a través de scale_fill_gradientn. A esta función solo debemos asignarle una cantidad de colores, y lo que hace es generar las transiciones entre ellos para generar el gradiente de colores. Aquí es donde usamos las paletas que RColorBrewer nos ofrece (http://colorbrewer2.org/). la función brewer.pal nos pide solo dos argumentos: la cantidad de colores y la paleta. Luego, en name indicamos el título de la leyenda. Los caracteres \n son interpretados como un enter en la paleta. Prueben cambiar la paleta “Blues” por la paleta “Oranges” o "Reds.
Todavía podemos mejorar sustancialmente el gráfico. Por ejemplo, con el siguiente código:
mapa <- ggplot(data = datosCalidad, aes(fill = indiceCalidad)) +
geom_sf(colour = NA) +
scale_fill_gradientn(colours = brewer.pal(n = 5, name = "Reds"),
name = "Viviendas de calidad insuficiente (%)",
guide = guide_colourbar(
direction = "horizontal",
barheight = 0.8,
barwidth = 16,
title.position = 'top',
title.hjust = 0.5))
mapa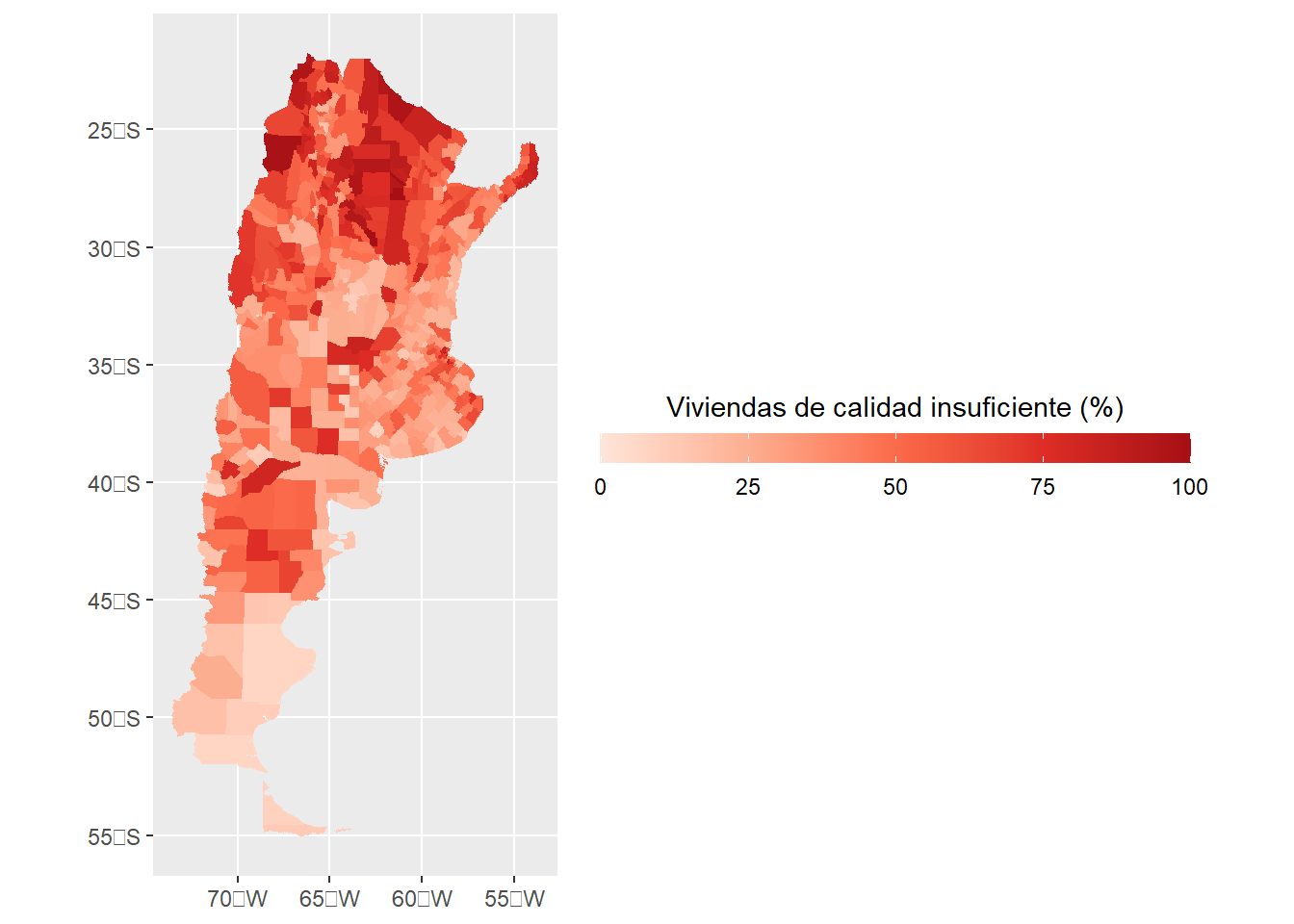
¡Mucho mejor! Pero hay varias cosas que incluímos, vamos a explicarlo paso por paso. En primer lugar, ya no hay línea divisora entre los polígonos, recomiendo enfáticamente removerlos cuando las unidades son muchas, pequeñas y el mapa no es interactivo, esto lo hacemos mediante colour = NA dentro de geom_sf.
Luego, dentro de el espacio donde definimos la paleta scale_fill_gradientn agregamos una colourbar, que lo que haces es modificar la leyenda dándole un mejor aspecto. Podemos elegir la dirección (en este caso, horizontal), debemos elegir tanto su largo como su ancho, elegir la posición del titulo y elegir su “justificación”, que es básicamente lo que hacemos en word eligiendo si queremos que el texto se “pegue” a la parte izquierda, este centrado o se “pegue” a la parte derecha. hjust = 0.5 lo deja centrado. Los tamaños en ggplot2 están representados en milimetros, suponiendo que en cada pulgada hay 72 puntos (72 PPI), vamos a volver a esto un poco más adelante.
Noten algo más: guardamos nuestro gráfico en un objeto que se llama “mapa”. De ahora en más podemos ir modificando este objeto agregándole capas con + como estuvimos haciendo hasta ahora. Vamos a cambiar ese fondo gris que no queda bien:
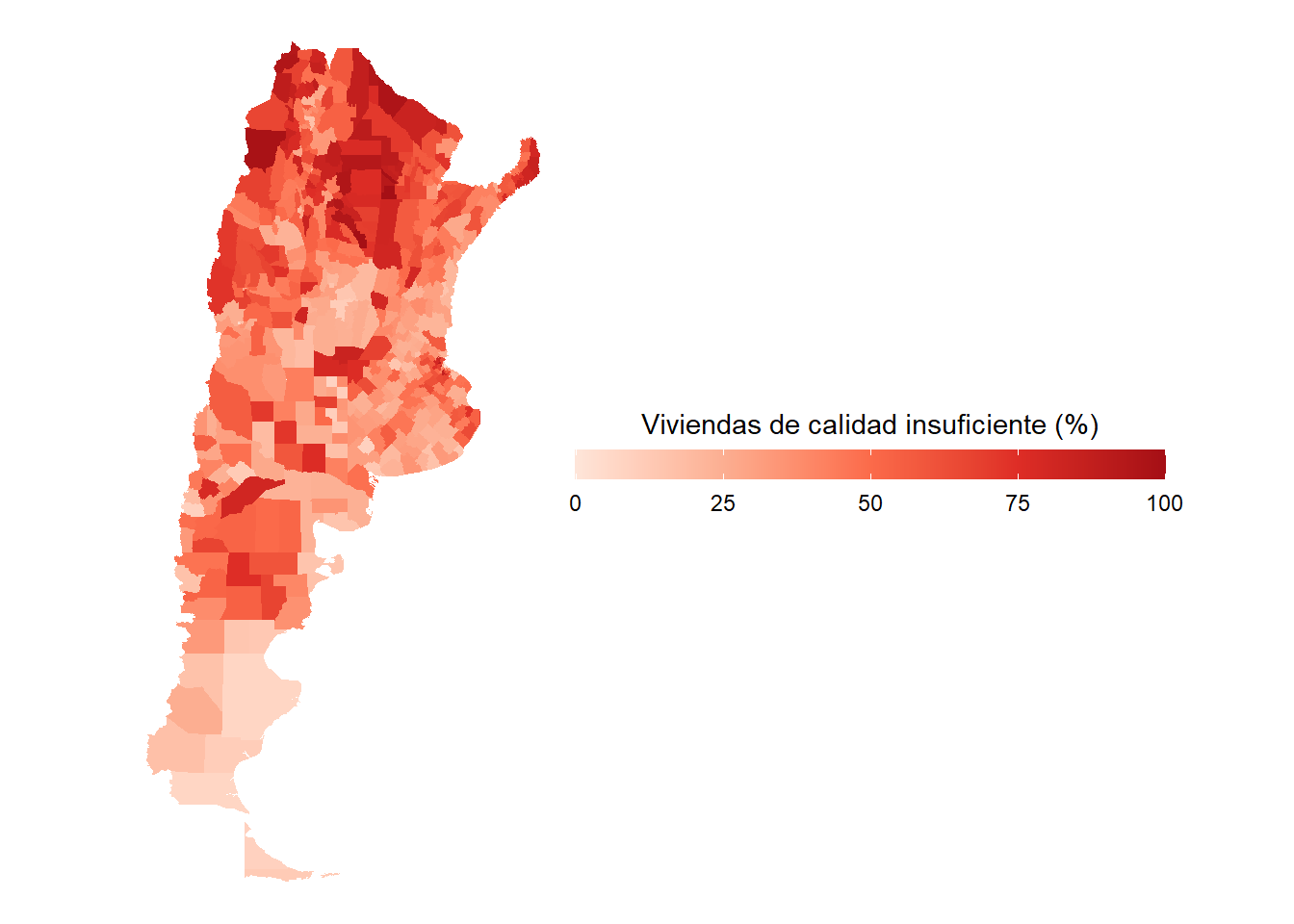
Como ggplot2 trabaja por capas, le asignamos un conjunto de formatos mediante la función theme_void. Los temas (themes) predefinidos son muy útiles ya que nos ahorran mucho código de formateo de la visualización. el paquete ggthemes contiene varios themes muy interesantes, como los del Wall Street Journal, Five Thirty Eight o Stata, más adelante vamos a probarlos. Probemos qué hubiera pasado con aplicando otro theme:
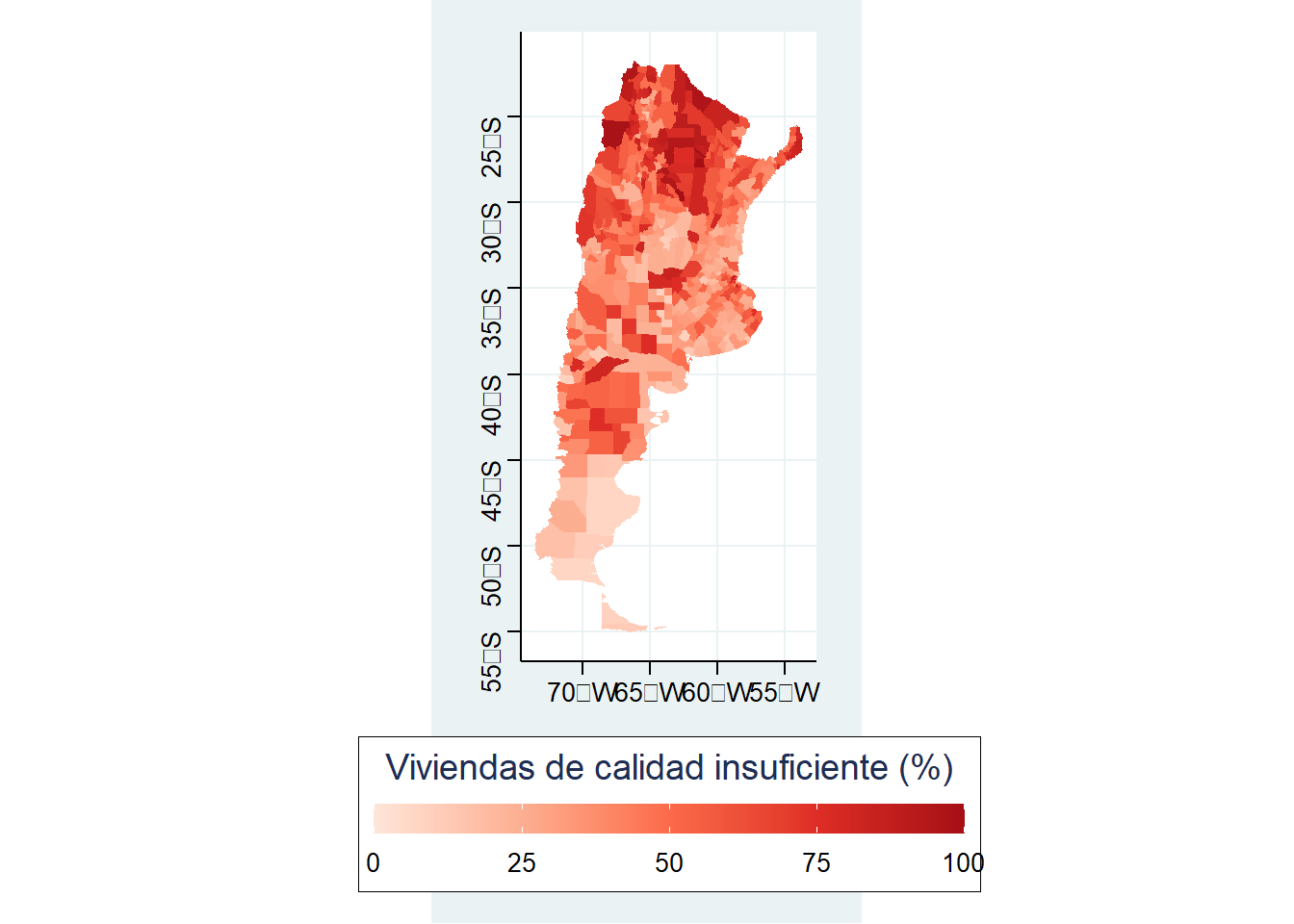
Bien, ahora querríamos colocar la colourbar abajo, tal como hace el theme_stata(), y también remover las líneas de fondo. Estas modificaciones se pueden hacer dentro de la función theme(). Dentro de ella elegimos los objetos y los modificamos. Por ejemplo, en legend.position decimos dónde queremos la leyenda ,en este caso la queremos abajo del gráfico y por eso usamos “bottom”. Luego, tomamos la grilla de fondo “panel.grid.major” y a la línea le asignamos un color transparente. También seteamos algunos parámetros para el título (que esté centrado, que tenga tamaño 16 y que esté en negrita) y el título de nuestra leyenda.
mapa <- mapa + theme(legend.position = "bottom",
panel.grid.major=element_line(colour="transparent"),
plot.title = element_text(hjust = 0.5, size = 16, face = 'bold'),
legend.title = element_text(hjust = 0.5, size = 12))
mapa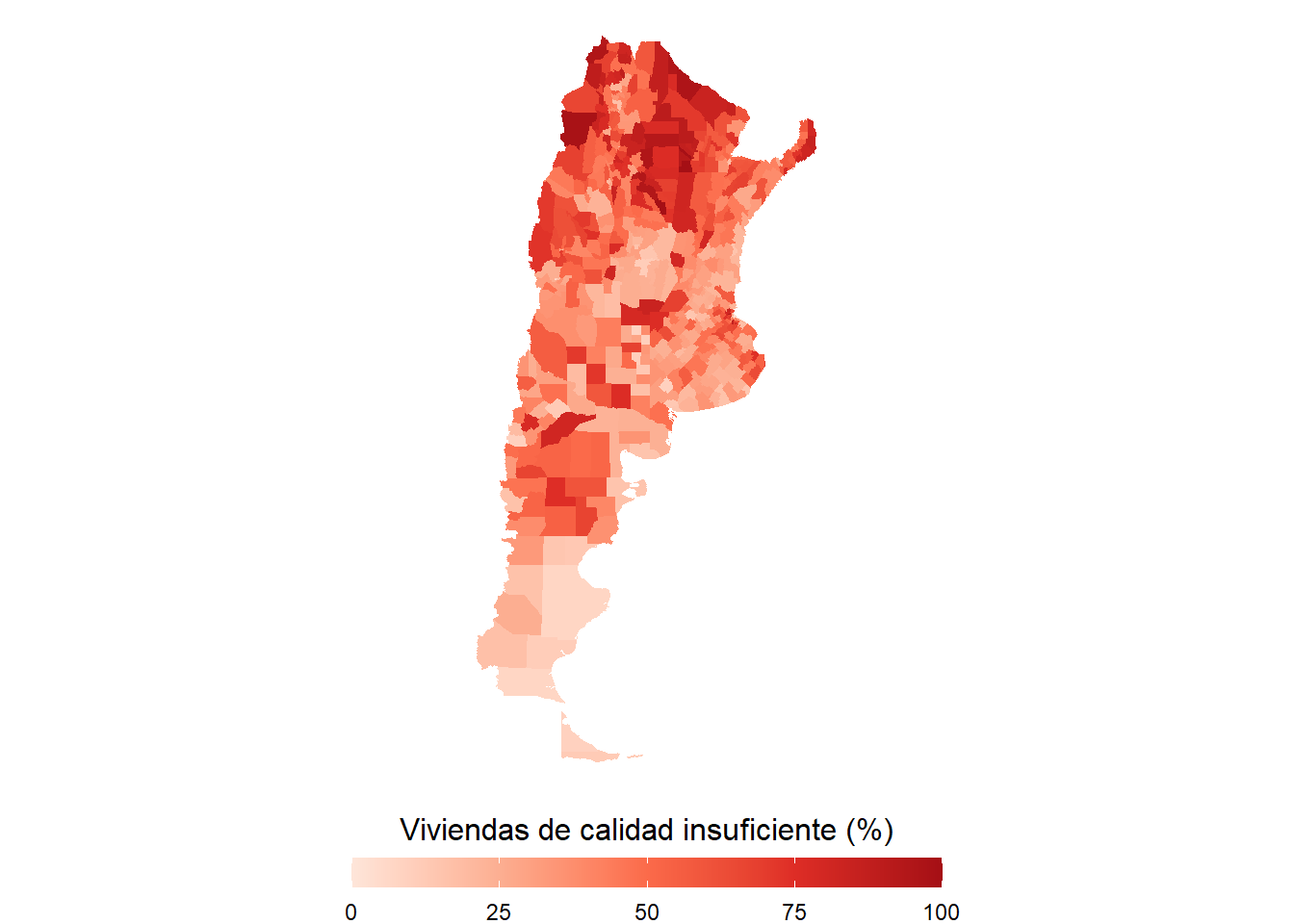
Solo nos queda agregar un título y una fuente:
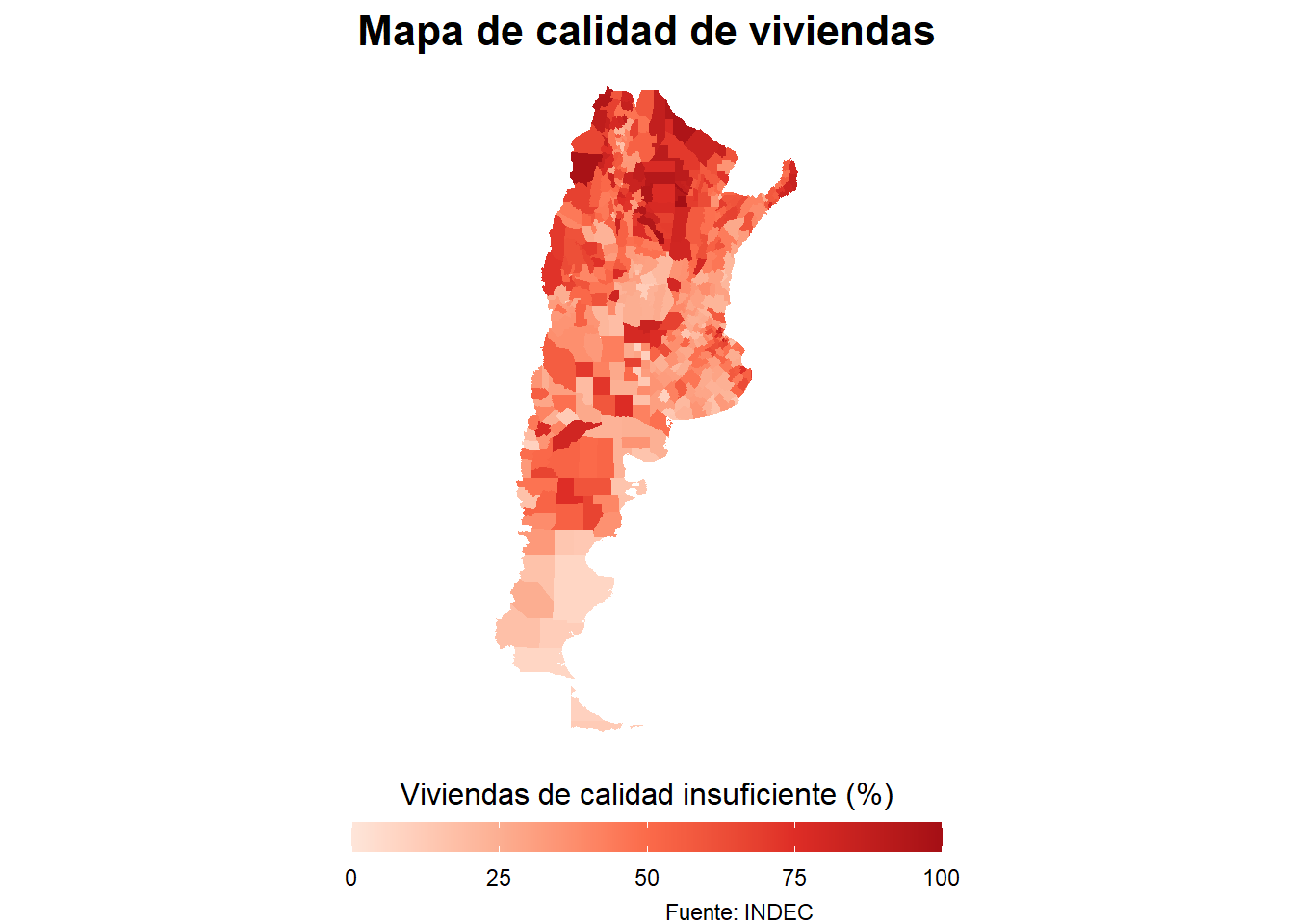
Ahora nuestro gráfico quedó mucho mejor. Pueden guardardo desde “Export”, aunque rápidamente van a darse cuenta, cuando vayan cambiando las dimensiones de los plots, que a medida que lo hacen más grande, el texto queda más chico. Además, solo pueden exportar el formato del tamaño del planel multiuso. Pero no se preocupen, hice una función que hace todo esto más fácil: van a poder elegir el ancho y alto en píxeles y después solo tienen que elegir cuánto quieren que se agrande el texto. Ejecuten el siguiente código:
# Source ejecuta código R de otros archivos
source("https://raw.githubusercontent.com/datalab-UTDT/datasets/master/auxiliares.R")
plot.save(plot = mapa,
width = 500,
height = 1000,
filename ='mapa.png',
bg = "#f5f5f2")
plot.save(plot = mapa,
width = 1000,
height = 2000,
text.expansion = 2,
filename ='mapaText2.png',
bg = "#f5f5f2")¿Qué patrón observan en el mapa? Por lo que vemos, el norte del país muestra los peores valores en nuestro indicador, especialmente en las provincias del noreste.
6.2.2 Tmap
Aun siendo muy útil para nuestros mapas, Gplo2 es mucho más útil para otro tipo de visualizaciones. Para hacer clorophets, una de las visualizaciones más típicas, el paquete más simple y que más utilizarán es tmap. Ya lo hemos usado en otras ocasiones, y veamos cómo podemos hacer lo que hicimos con ggplot2 de una manera más simple:
tmapClorophet <- tm_shape(datosCalidad) +
tm_polygons(border.col = "transparent", col = "indiceCalidad",
palette=brewer.pal(n=5,"Reds"),
title = "Viviendas de \ncalidad \ninsuficiente") +
tm_layout(legend.format = list(text.separator = "-"),
main.title = "Mapa de calidad de viviendas",
main.title.size = 0.8,
frame = FALSE)
tmapClorophet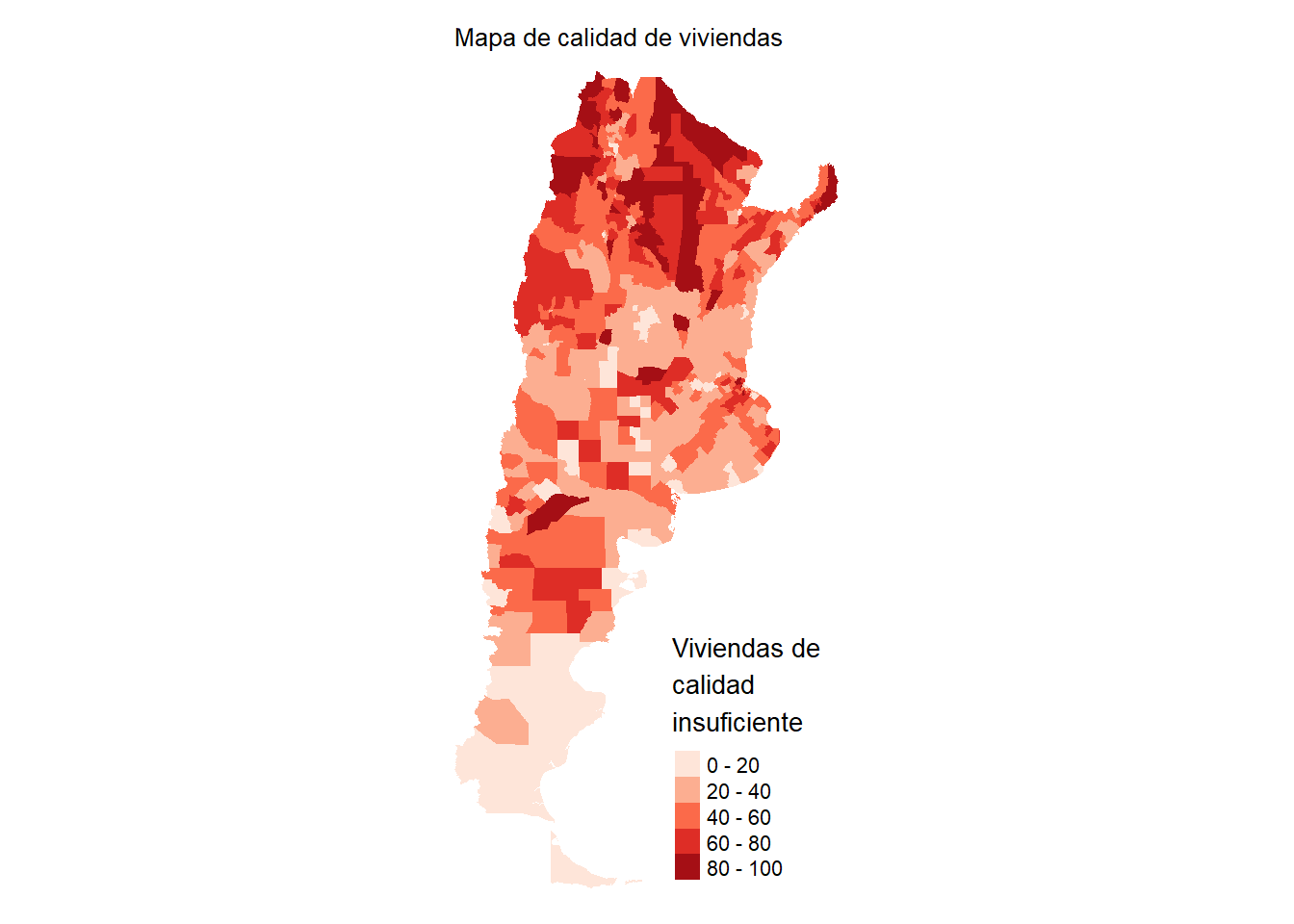
Como vemos, la sintaxis es relativamente similar a ggplot2. Primero debemos informar cuáles son los datos dentro de tm_shape (en este caso, datosCalidad). Luego indicamos qué queremos graficar: polígónos (tm_polygons). Al igual que en el anterior gráfico, no queremos que haya divisiones entre los polígonos así que lo pasamos a “transparent”. Elegimos el color por el cual queremos que rellene los polígonos con col, la paleta con palette y el título de la leyenda con title. Luego, con tm_layout() modificamos el aspecto de la leyenda, específicamente el separador entre las categorías (en lugar de “to”, que use “-”). Cambiamos el título y sacamos el frame que viene por default ¡Muy fácil!
Todavía más, con estos mapas podemos discretizar rápidamente nuestros plots. Por default nos genera las 5 categorías que dividen a la variable (de 0 a 100). En lugar de eso, podemos mejorar esta aproximación al graficar en 4 categorías a los departamentos de tal manera que en cada una de estas categorías se acumule aproximadamente la misma cantidad de departamentos. Estos son los quintiles de una distribución y tmap nos hace el trabajo muy fácil.
tmapClorophet <- tm_shape(datosCalidad) +
tm_polygons(border.col = "transparent", col = "indiceCalidad",
palette=rev(brewer.pal(n=4,"RdYlGn")),
breaks = quantile(datosCalidad$indiceCalidad),
title = "Viviendas de \ncalidad \ninsuficiente") +
tm_layout(legend.format = list(text.separator = "-"),
main.title = "Mapa de calidad de viviendas",
main.title.size = 0.8,
frame = FALSE)
tmapClorophet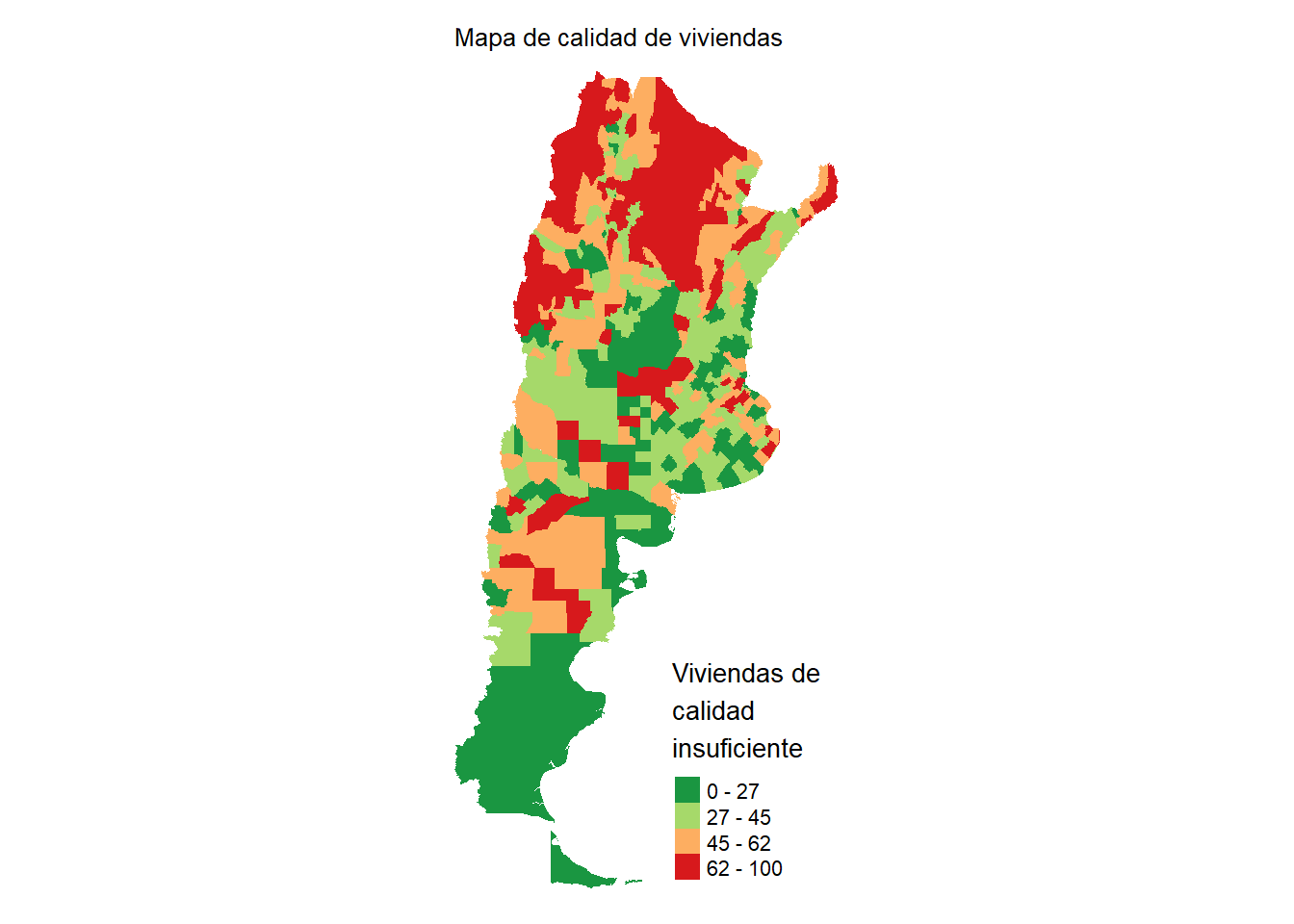
La clave fue el argumento breaks, donde indicamos dónde queremos que corte a la variable. quantile() corta en cuatro porciones a la variable índice de calidad, mientras que usamos otro tipo de paleta y, ademas, invertimos el orden usando rev().
Vamos a mejorar nuestro gráfico utilizando simultáneamente los polígonos de las provincias de Argentina. Podrían repetir el procedimiento leyendo los shapefiles con el comando readOGR tal como hicimos con los departamentos. Sin embargo, para aprender a leer otro tipo de archivos donde se guardan datos espaciales, vamos a usar la función st_read y leer un archivo geojson:
mapaProvincias <- read_sf("https://github.com/datalab-UTDT/datasets/raw/master/provincias.geojson")
mapaProvincias <- mapaProvincias[-24,]tmapClorophet <- tm_shape(datosCalidad) +
tm_polygons(border.col = "transparent", col = "indiceCalidad",
palette=rev(brewer.pal(n=4,"RdYlGn")),
breaks = quantile(datosCalidad$indiceCalidad),
title = "Viviendas de \ncalidad \ninsuficiente") +
tm_layout(legend.format = list(text.separator = "-"),
main.title = "Mapa de calidad de viviendas",
main.title.size = 0.8, main.title.position = 'center',
frame = FALSE) +
tm_shape(mapaProvincias) +
tm_borders(col = "white")
tmapClorophet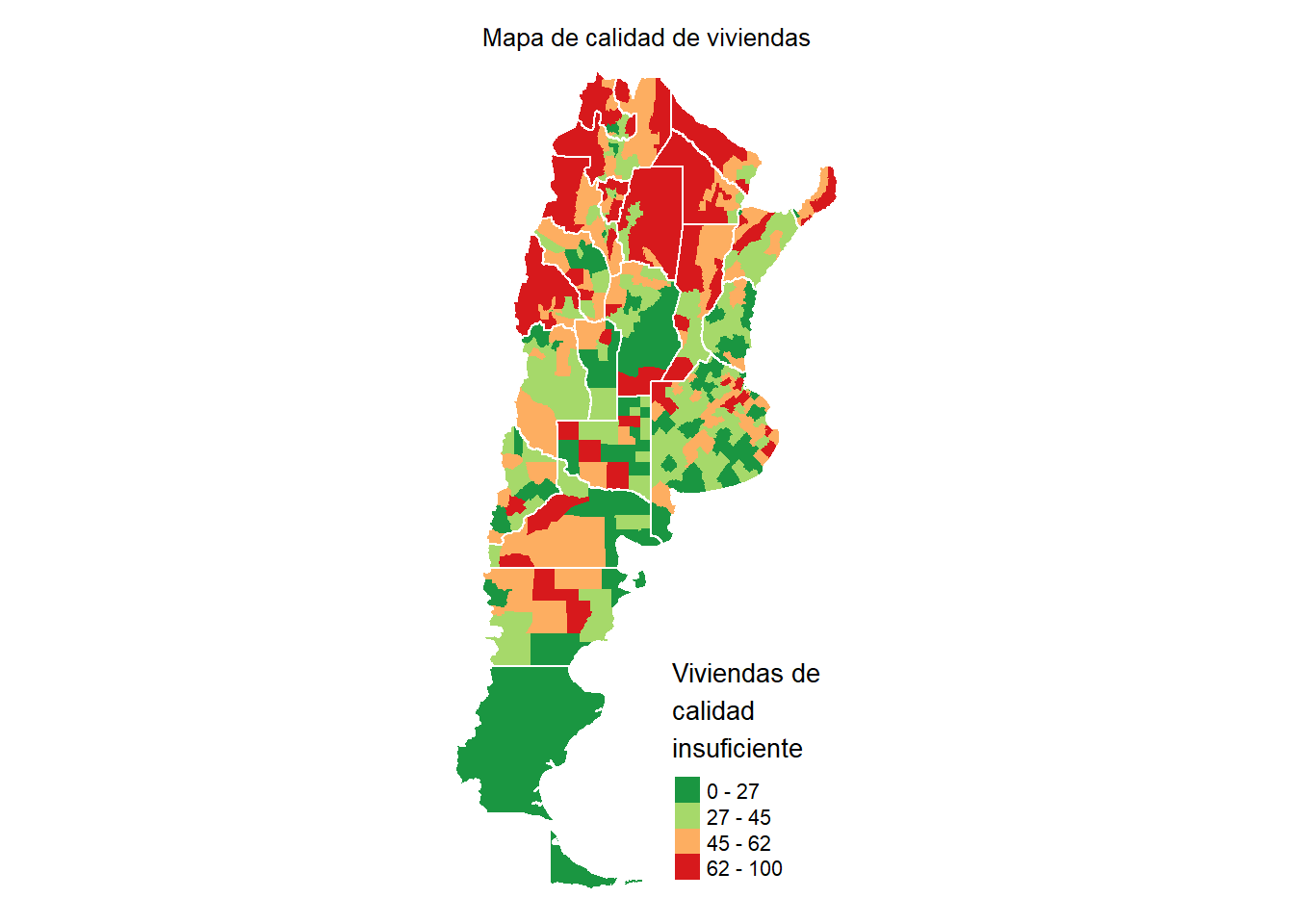
Ahora podemos ver como guardar un objeto tmap usando save_tmap. Tener en cuenta que el ancho y el alto en este caso tienen que multiplicarlo por 300 para conocer el tamaño en píxeles total (esto es porque tiene predefinido ppi=300). Por ejemplo, el archivo “tmapClorophet.png” debería tener 900px de ancho.
6.3 Leaflet
Hasta ahora hemos estado trabajando con gráficos estáticos. En muchas oportunidades son útiles, y cuando debemos hacer reportes o determinadas presentaciones son nuestra única opción. Sin embargo, los mapas interactivos nos permiten consultar los datos de una manera distinta y son una buena alternativa para compartir las visualizaciones. Vamos a ver un simple ejemplo de utilización de Leaflet, mostrando las mismas visualizaciones que estuvimos haciendo hasta el momento para los datos del censo.
Todas las visualizaciones de leaflet deben comenzar con la función leaflet() y, a diferencia de ggplot2 y tmap, en leaflet usamos %>% para ir agregando las capas. addTiles() plotea la “imagen” del mundo, si no usamos esa función solo veremos un output gris
Ahora deberíamos indicar qué tipo de figura deseamos agregar. En nuestro caso, queremos agregar polígonos, por lo que usaremos la función addPolygons
Debemos rellenarlos con los valores correspondientes al índice de deficiencia de viviendas que armamos anteriormente. Para eso tenemos que crear una paleta, como ya hicimos en ggplot2 y tmap. En Leaflet lo que tenemos que usar es la función colorBin. A ella le pasamos una paleta de RColorBrewer, en orden reverso para que vaya desde verde (valores más bajo) a rojo (valores más altos). Al mismo tiempo, seteamos a FALSE los bordes de los polígonos (stroke=FALSE) y la opacidad a 1 del relleno (fillOpacity=1) para que veamos correctamente los colores.
pal <- colorBin("RdYlGn", reverse = TRUE,
domain = datosCalidad$indiceCalidad,
bins = quantile(datosCalidad$indiceCalidad))
leaflet() %>%
addTiles() %>%
addPolygons(data=datosCalidad,
stroke = FALSE,
fillColor = ~pal(indiceCalidad),
fillOpacity = 1)Para terminar, vamos a agregar los labels, es decir lo que aparece cuando nos posicionamos sobre alguno de los polígonos. Esto lo hacemos con el arugmento label dentro de los polígonos. Al igual que fillColor, debemos pasarlo como fórmula, es decir usando el prefijo ~, y luego usamos la función paste0, que como ya hemos visto en clases anteriores “pega” o colapsa los vectores. En este ejemplo queremos que diga el nombre del departamento, dos puntos, el valor del índice de calidad y luego el signo %. Además, agregamos el contorno de las provincias agregando otra capa de polígonos, pero sin relleno y solo con el contorno en blanco
6.4 Ejercicios
En la carpeta de datos del censo todavía hay dos archivos csv que no usamos: los datos de hogares y de individuos. Usando nuestro dataset de viviendas, unan los hogares a las viviendas y, luego, los hogares a los individuos. Una vez que tengan el dataset con los individuos, y el departamento al que pertenecen, creen un mapa con tmap, tal como hicimos con el índice de vivienda, pero ahora con la edad promedio por departamento (tener en cuenta que la variable “años cumplidos” es la P03)